Stop buying ‘master prompts’
Understand LLMs and get consistent results with ChatGPT, Claude, and Perplexity (and whatever comes next)
If a “master prompt” costs money, it’s usually not because it’s valuable. It’s because it saves you from thinking. And with LLMs, that’s exactly what makes your results unreliable.
ChatGPT isn’t “the AI”. It’s an interface to a Large Language Model (LLM). Claude is another interface to another LLM. Perplexity is an interface that often adds search and sources.
You’ll see this pattern across many products:
- General LLM chat tools: ChatGPT, Claude, Google Gemini, Microsoft Copilot
- Search plus sources tools: Perplexity (and similar “answer with citations” products)
- Tools embedded in work apps: Copilot inside Microsoft 365, Gemini inside Google Workspace, Notion AI, Slack AI features
- Developer and writing assistants: GitHub Copilot, Cursor, etc.
These are examples, not the point. The point is the underlying LLM behaviour. Different tools, same principle. But none of them removes the need for clarity.
Once you understand how LLMs behave, you stop hunting for magic prompts. You start getting consistent outcomes.
What an LLM actually does
An LLM predicts the next token (word piece) based on the context you give it. That’s why it can sound fluent, helpful, and confident. And that’s also why it can be wrong. It is not “looking up facts” unless the tool is connected to search or your own data. It is generating a plausible answer.
So the goal is not to find the perfect prompt. The goal is to control the context and the constraints.
What these tools are (and what they are not)
LLM tools are great at drafting, structuring, summarizing, and exploring options. They are not a perfect source of truth. They can hallucinate. They do not have judgement. They do not take responsibility.
Treat them like a fast assistant. You own the outcome.
Why “master prompts” fail in real work
A master prompt assumes your situation is generic.
Real work is not generic.
Your goal, your audience, your constraints, your data, your risks, your definition of “good” are specific.
A copied prompt can’t know that.
So people copy a prompt, get a mediocre result, and conclude they need “better prompts”.
What they actually need is a better briefing.
One short example: master prompt vs good briefing
Master prompt thinking:
“Write a professional project update email for my stakeholders.”
Good briefing thinking:
“I’m the project lead. I need a short update email for senior stakeholders who care about risk and timeline. Context: we’re migrating a legacy data warehouse to a modern platform. This week we finished X, we’re blocked on Y, and we need a decision on Z. Keep it under 150 words. Use clear owners and next steps. If anything is uncertain, flag it.”
Same tool. Completely different outcome.
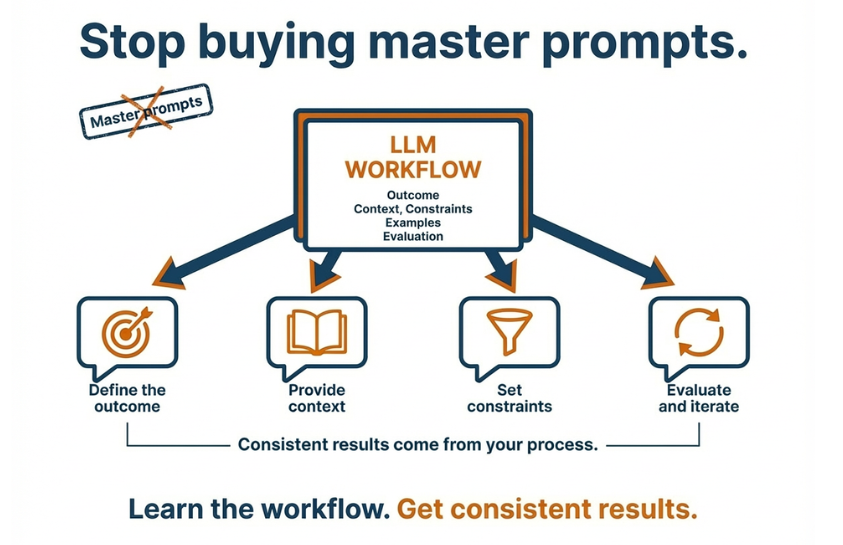
A simple mental model for writing good prompts (no templates)
If you want consistent output, think like this.
1) Start with the outcome
What should exist at the end? Be concrete.
“Summarise this document into decisions, risks, and next steps.”
“Draft a client email that proposes 2 options and asks 3 questions.”
2) Provide the context that matters
Context is your leverage.
- Who is the audience?
- What is the situation?
- What is true, and what is not?
- What constraints apply (length, tone, compliance, terminology)?
- And also: who are you in this situation? Are you the decision maker, the analyst, the consultant, the product owner, the person doing delivery?
That role changes what “good” looks like.
3) Set constraints and quality criteria
Define what “good” looks like. Short. Practical. No hype.
If something is uncertain, say so.
4) Ask it to show its work
This is how you reduce confident nonsense. Ask for assumptions. Ask what should be verified. Ask for alternatives and trade offs.
5) Iterate like you would with a colleague
First outline. Then a draft. Then tighten. Then validate. Small steps beat one giant prompt.
Closing
If you want to get value from LLM tools, stop hunting for master prompts. Learn the model. Brief clearly. Validate outputs. Own the outcome.
If this resonates, share it with someone who’s about to buy a prompt pack.
Clarity. Ownership. Outcomes.
DaAnalytics is my personal label. Bravinci is the partner network I deliver with. Same standard in both places: craft-led work, clear agreements, and measurable impact.
I help mid-market teams turn messy data into decision-ready insight with governance, predictable delivery, and outcomes you can measure.
Originally published at
https://www.linkedin.com